When building a database system with servers and disk arrays, it is not immediately obvious how to best utilize the available drive bays to create an optimised database storage setup. Let’s look at some requirements.
Requirements
The biggest considerations when selecting a storage solution are:
- High-availability (HA): the system must fail gracefully not catastrophically. This means that some form of RAID must be used and hot spares should be available.
- Disaster recovery (DR): in the case of data loss or corruption we need to be able to restore the database from a backup. This must take RTO and RPO into account. Can the backups be compressed?
- Capacity: How much data is expected to be stored in the system? Usually the data volume grows continuously, so the capacity is often calculated with respect to the lifetime of the hardware.
- Transaction intensity (IOPS): How much throughput should the disks handle? Remember stripping across small disks is preferred. The advent of SSD is starting the change all that with Oracle now able to handle tiered storage types.
Storage options
While the database may need high-performance SAS/FC disks or SSD, the backup disks only have to perform sequential reads (database restore) and writes (database backup), and so can make do with slower TB SATA disks.
So looking to your vendor, there will be a range of different solutions available. Some servers (rack-mounted) will have in-built storage capacity ranging from 2 up to 25 bays. Other servers will have just two internal disks for the OS and database application, and will instead be connected via FC to a dedicated disk array solution to provide storage. Disk arrays include all the features needed for creating an HA storage solution.
Next are the disks. FC disks are the most expensive, but with the advent of competitive SAS disks are not worth the money unless you need every once of performance you can get. Disks come in various sizes and for the database the relatively small 300GB or 600GB SAS disks are a good choice. For the backup there are 1TB or 2TB SATA disks available.
Capacity
Once the choice of disks is made, then it is possible to calculate the number of disks needed. This has to take three things into account: 1) RAIDing will consume 20-50% of the raw disk capacity, 2) the remaining disks shouldn’t be filled to more than 50%, though in practice 70% is usually an acceptable planning capacity and 3) that a minimum of two hot spares are needed. The logic is that during the time it takes to replace a spare disk, the disk array will still be providing HA with the remaining hot spare.
Calculating capacity can be tricky. When selecting a 300GB from the vendor, this is the SI definition of a Gigabit which is 1000000000bits. However, from the OS point of view the disk is 279GiB which is a somewhat smaller value but is using the traditional binary-based Gigibit definition. So when asking the sales team what capacity they need for the customer just be clear which dimensions they are using to avoid embarrassment later.
OK, so finally to the DR requirement, how much backup storage is needed? Well let’s assume we want to use uncompressed backups, this is less processor intensive and will result in faster restore times. In this case, the backup size is the size of the database. On day one we make the first full backup. On day two we make a new full backup, but we can’t delete the first backup until the new backup is completed so there must be sufficient space for two full uncompressed backups. In my experience, the last two full backups were saved due to the critical nature of the data, so this required a backup storage capacity that was three times the size of the planned database capacity.
Solution portfolio
Now, we have examined all of the requirements for creating a high-performance, highly-resilient database solution that matches the customers capacity and performance requirements. But this case-by-case dimensioning process is a time-consuming analysis that doesn’t scale well. Instead, we want to create and maintain a portfolio of standard database solutions that the sales teams can just pick from. This means that all the calculations are performed once in advance. This strategy also aligns itself with creating filled disk array configurations since disk arrays are expensive compared to the disks themselves (especially SAS and SATA disks). The choice we have in deciding which hardware components to use becomes instead a choice the customer can make to get the best value for money.
Example: HP DL380P
Let’s apply all of these rules to a HP DL380P solution that has a 25 disk SFF (2.5″) backplane. The SFF backplane is needed because the database needs many small fast disks, which means that all disks in the server will have to be SFF including the ones used for backup. The two disk sizes available in SFF are 300GB and 600GB.
The 25 disk bays are divided into three groups, one for the OS and database application, one for the database storage and one for backup. The OS and application don’t need much space so one mirrored pair of 300GB disks will suffice.
For the database storage 300GB disks will be used and for the backup the 600GB disks. So, how do we divide the remaining 23 disk bays between storage and backup? This is a process of trial and error. First, we allocate two bays for hot spares for the database. Then we pick a RAID strategy; RAID 1+0 (mirroring then stripping) provides the best performance but with the result that half the disks are used for redundancy. Hot spares for the backup storage would be overkill and RAID 5 provides sufficient performance with a capacity loss of just one disk for parity.
The final configuration looks like this:
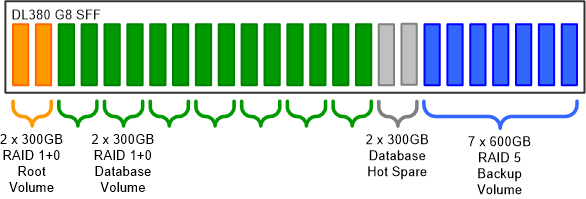
And here is the math:
| Database storage | |
|---|---|
| Raw disk capacity | 4500GB (16 x 300GB) |
| Hot spares | 2 |
| Redundancy strategy | RAID 1+0 |
| Usable capacity | 1470GB (7 x 300GB x 70%) |
| Reported capacity | 1953GiB (7 x 279GiB) |
| Backup storage | |
|---|---|
| Raw disk capacity | 4200GB (7 x 600GB) |
| Hot spares | 0 |
| Redundancy strategy | RAID 5 |
| Usable capacity | 3600GB (6 x 600GB x 100%) |
| Reported capacity | 3354GiB (6 x 559GiB) |
| Ratios | |
|---|---|
| Database usable/raw | 32% (1470GB/4500GB) |
| Database usable/total | 17% (1470GB/(4500GB + 4200GB)) |
| Backup usable/raw | 85.7% (3600GB/4200GB) |
| Backup/database | 2.45 (3600GB/1470GB) |
From this example we can create a high-performance database configuration with a usable database capacity of 1.47TB. The ratio of backup to database storage is 2.45 which means that there is space for one backup plus the creation of a new backup. To allow for two full backups to be saved, two more disk bays could be allocated to the backup storage, lowering the database capacity to 1.26TB. Alternatively, the marketed capacity could just be lowered to 1.2TB (3600GB/3) which may be more flexible.
The actual usable storage space as a percentage of the total is also interesting. Just 17% or 1.5TB of the total 8.7TB can be used to store application data.
Finally, two of these database configurations (a primary and secondary) are needed to provide redundancy at the database application level. This is for two reasons: 1) in case of database application failure (a failover) or 2) for maintenance operations on the primary (a switchover).