The purpose of a reference architecture is to identify the architectural principles that apply when creating a sustainable and scalable solution. As new additions are made to the solution, the reference architecture becomes the yardstick that all solution proposals can be measured against and so enable a fair comparison of ideas.
A key test of the principles used to create an architectural model is whether they display conceptual integrity. Proposed solutions and additions to the solution must respect the conceptual integrity and show where they deviate from said principles as well as motivating why it was necessary to do so.
Deviating from these architectural principles is often (well-)motivated for reasons of time and cost when implementing the solution. However, without an explicit reference architecture one cannot measure the effect of these compromises, compromises that generally result in higher maintenance costs. And the larger the deviations from the reference architecture, the greater the risk for higher maintenance costs and the harder it will be to continue developing and scaling up the solution in future.
For over time, the tendency is always towards greater and greater divergence between the solution and the model; until finally the conceptual integrity of the solution can no longer be discerned. How then do we preserve the conceptual integrity? By training and information dissemination, what is known as shared understanding as preached in the Agile world. The development team must share the same picture of the reference architecture if it is going to be maintained going forward; and it will also be much easier to explain how a solution works if it adheres to architectural principles compared to one that does not.
An essential part of a reference architecture is the creation of architectural artefacts, such information models, state machines, process diagrams and so on. Using standard modelling notation such as UML and BPMN reduces the risk for ambiguity and makes knowledge sharing that much easier.
Where to start? Try to identify what type of solution it is you are building. Does it fit into a known pattern? Try to find the appropriate technical literature (in book format and online) that provides a frame of reference (including vocabulary), and use it to create a reference architecture which can then be applied to the solution.
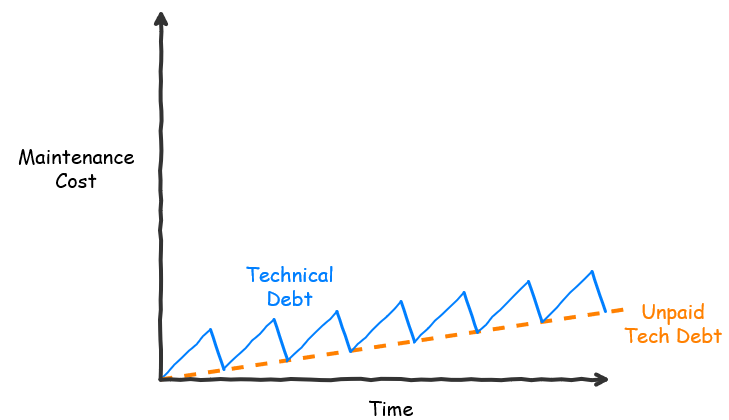
Agile software development is about adapting to change, about continuously learning what the customer wants. The team breaks down the solution into small pieces, delivering working software in every iteration that the customer can evaluate and give feedback on. In order to be able to learn faster, the initial releases may sacrifice best practice (in a controlled way), for example, a lack of abstraction, using tightly-coupled modules, hard-coded values, a crude data model, etc. In extreme cases, the developers “build one to throw away” (Fred Brooks). These are all forms of Technical debt (as Ward Cunningham defined the term); deliberate shortcuts in the implementation that we then remove when our understanding has improved.
The key point is that this is a debt that has to be paid back as soon as possible; a short-term loan if you will. Ward describes repaying the debt as using the experience gained from customer feedback to refactor the code to reflect the team’s new understanding of the problem. This chimes well with what Fred Brooks describes as maintaining the Conceptual Integrity of the product. Martin Fowler describes this as Prudent Deliberate debt. Henrik Kniberg calls it Good Technical Debt.
Unfortunately, the world is not perfect and Technical debt is not always repaid (in full). This results in the phenomenon of software entropy; the gradual disorder that arises as the code is modified over time. Martin describes the ways the team can default on their debt in his Technical Debt Quadrant: Reckless Deliberate debt will have to be postponed, and some or all Inadvertent debt will be discovered too late to do anything about within the timeframe of the project. Henrik calls this Bad Technical Debt.
This unpaid Technical Debt now becomes added to the long-term maintenance backlog of the product. This backlog also includes work that results from advances in technology and the deprecation or obsolescence of existing technologies, amongst other things. Meaning, even if we could develop the best possible solution using state-of-the art technologies today, we would still incur debt in the long-term because of obsolescence. This is a long-term loan that must also be repaid as we develop new features.
This long-term debt has also, confusingly, become labelled as Technical debt, a result of semantic diffusion. Uncle Bob addresses this in A Mess is not Technical Debt. This unclear distinction is understandable: from the point-of-view of the Product Owner who is trying to deliver a new feature, it makes no difference if the debt is short-term or long-term, it still has to be paid whether it was incurred as part of the project or as a result of longer-term software entropy or (for example) obsolescence. However, I would argue that Technical Debt is contracted debt, debt that the PO and development team have agreed on incurring as part of the learning process. In that case, long-term debt could be seen as a form of implicit rent.
What can we call this phenomenon of long-term debt? Let’s look at what constitutes it:
Obsolescence: new versions or EOL for third-party software, engineering competence not available, etc.
Software entropy (Unpaid Technical debt): a lot of Reckless Deliberate debt, nearly all Inadvertent technical debt (frequently labelled incorrectly as “accidental complexity”).
All these phenomena affect the viability or vitality of the software solution, in other words we are talking about the technical durability of the solution. If nothing is done we will reach an inflection point (debt ceiling) where it costs too much to develop new features in the existing solution and a fresh start will be needed. Perhaps an appropriate name for all this long-term debt is simply Maintenance Debt.
As Martin wrote, it is the usefulness of these terms that is relevant. We want to distinguish between the Prudent deliberate debt incurred by the project and everything else that requires maintenance. By naming the longer-term debt as Maintenance Debt we can return Technical debt to its original definition: a short-term debt that is deliberately incurred within the context of the project, and which is budgeted for.
In contrast, Maintenance debt encompasses long-term debt which the team have little control over, may or may not be part of any feature development and most likely has not been budgeted for.
Integration platforms create a useful abstraction layer and are a prerequisite for building a Service Oriented Architecture. The integration platform is often the domain of an “Integration team” which may reside in-house or be out-sourced.
When building new services, one of the first things that has to be done is to create the service specification, which defines how the integration platform will publish your service. For SOAP web services this is done using WSDL. The integration team is then responsible for translating messages between systems, mapping fields, etc.
In some cases the integration work involves packaging a specific functionality of an existing legacy service and publishing it as a more intuitive and lightweight service that can be more easily consumed by modern clients. If the clients are under development, then the scope for the integration team may not be 100% specified. To compensate, the integration team can include mappings that might be needed. This can result in a service that contains more functionality than is strictly necessary to create a working solution.
When end-to-end testing is performed any problems found will be fixed, but only for that portion of the new service that is actually used by the client. Furthermore, the integration team may not have tested all or indeed any of the features of the service they created, instead relying on the end-to-end testing to find problems.
The result is an integration service that fulfils the client’s requirements but includes features that are untested. The integration team document the entire service but have no idea how much of the service has actually been verified to work. This creates a maintenance headache when the service must be modified.
The presence of superfluous fields is an obvious problem. A more subtle issue are fields that support specific values (like enums) where clients use some values but not all. The service provider might allow values A,B,C,D,E,F, the integration documentation might only advertise A,B,C,D, and the client might only use A and B. In reality, the integration may allow all values if no validation is applied; however all that has been tested are A and B. Since the integration team do not have in-depth knowledge of the client behaviours, they have no alternative but to rely on their own code and documentation to understand the scope of the service.
In conclusion, once a service has been created that is too big for purpose, it is difficult if not impossible to reduce its functionality. Ideally, the service should be built up incrementally in an agile way-of-working, this ensures that the client and the integration are fully meshed. This method may not be possible with out-sourced integration teams. Another alternative is for the integration team to create a mock client that verifies the whole service even if no client actually exists that will use all of the service’s functionality. This at least would enforce a cost constraint on the integration team that will hinder the creation of services that are larger than necessary. Tools such as SoapUI and Postman can be used for this purpose.
When developers talk about publish-subscribe design patterns I immediately think of the newspaper analogy. As described in Head First Design Patterns:
A newspaper goes into business and begins publishing newspapers.
You subscribe to a particular publisher, and every time there’s a new edition it gets delivered to you. As long as you remain a subscriber you get new newspapers.
You unsubscribe when you don’t want papers anymore, and they stop being delivered.
While the publisher remains in business, people, hotels, airlines, and other businesses constantly subscribe and unsubscribe to the newspaper.
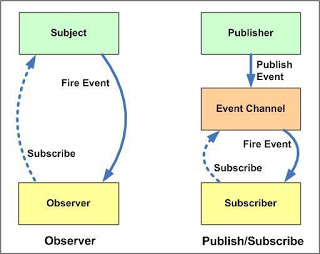
As a software design pattern, this is known as the Observer Pattern. In this pattern the publisher is called the Subject and the subscribers the Observers.
Comparison of Observer and Pub-Sub patterns
The Observer Pattern has some limitations such as scalability and hard-coupling. Unlike the physical world of newspapers it is possible to build an improved subscription service that does scale and is loosely-coupled. This improved pattern is called the Publish-Subscribe Pattern (or “pub-sub”).
Now you’re wondering, why name the pattern “publish-subscribe” when it does not behave like a newspaper pattern?? This has caused a lot of consternation in my discussions with other system architects. Unless one is aware of the naming convention used for these patterns; then it has happened that one person is talking about pub-sub and the other thinks they’re talking about newspapers.
It would be have been more intuitive to have called pub-sub something like the Scalable Observer Pattern.
As a software developer or architect you will probably have had at least one discussion about the difference between information models and data models. Why do we want to make this distinction? In practice drawing an information model is much the same as drawing a data model; both use the entity-relationship model for describing the world. ER-diagrams are easily transformed into the SQL used to create the table structure in relational databases (MySQL, MSSQL, etc.). So when do we need to create information models? Let’s look at an example.
Startup
ACME Trading has started a business selling pencils to its customers. They have set up a very basic ordering system to handle orders and ship goods to their customers. They designed a data model that will support the business software by examining the process (reality) of ordering goods and came up with the following:
The model has just two entities, one for the customer and one for the orders. These entities contain all the attributes needed to fulfil an order.
Growing
ACME is doing alright but they want to grow the business faster so they try doing some marketing. Again they build a simple application to support this business function. Examining the real world again they design the following data model.
The model contains just two entities; the customer again, this time with different attributes, and an entity called Contact Method.
Boom times
The marketing strategy is a success and ACME soon have to expand their operations and need to develop their existing systems to better handle the increased volume of customers and orders for pencils.
But now it’s becoming a hassle to have to create the customer in two systems and wouldn’t it be great if all customers created in the ordering system were also added to the marketing system automatically?
This shouldn’t be a problem as long as the two systems have compatible data models. In other words, a customer entity in the ordering system can map to a customer entity in the marketing system. But if it’s not possible, which system do we change? The ordering system is business critical so we may not want to mess with that one too much. However, ACME are thinking long-term and realise that they need a more robust representation of reality, one that the company can grow into.
At this point they go back to their view of reality and create a model that is independent of any system, a reference model if you will. This is called an information model. Or as Wikipedia explains:
An information model provides formalism to the description of a problem domain without constraining how that description is mapped to an actual implementation in software. There may be many mappings of the information model. Such mappings are called data models, irrespective of whether they are object models (e.g. using UML), entity relationship models or XML schemas.
The information model now serves two purposes. First, to aid future software design in creating robust data models, for example by supporting different customer address types. Secondly, to enforce a common terminology across the system landscape and in the documentation, e.g. a mobile phone number is to be called “Mobile number” when writing user stories, test cases, defining class names and methods, creating database tables, etc.
In order for the Ordering system and the Marketing system to be able to exchange information, they can try to map their data models to the information model. All the existing data models and information models are modelling reality so the differences really arise from how faithful or granular the data model is compared to reality.
An organisation can have many data models, usually one per system, but should only have one information model. Different parts of the organisation may only be interested in certain entities and relationships and may create an information model for the parts of reality they are interested in, but these partial information models are really all part of the same organisation-wide information model, even if a complete information model does not yet exist. In very large companies this may not be practical or desirable especially where autonomy between divisions is encouraged.
An information model is almost never implemented as-is in a system. Firstly, an information model will often contain more entities and attributes than any one system needs to implement. The reverse is also true: data models will contain application-specific artefacts as well, as entities needed to handle many-to-many relationships for instance. Secondly, data models are optimised for the specific system that utilises them, meaning the developers have combined entities and attributes in ways that improve the performance of the database. Again, information models should not constrain the implementation of the data model.
Going global
ACME have now decided to establish operations in Europe and have opened a sales and support office in Sweden. The company is now multilingual. While the reality of ordering, shipping and marketing goods is the same globally, each country uses their own language to describe it. So when the Swedish sales offices start sending Requests for Change back to HQ, they are using word like Kund for Customer and Beställning for Order. They are referring to the same thing but it is hard for the Swedish Sales people to discuss the changes needed with the English-speaking developers.
The different lingual groups need to agree on a common terminology, this can be neatly reflected in the information model (which also does not expose implementation details the way a data model does):
We can generalise and say that if English is the lingua franca of programming and programming languages, then there will always be a need to agree on the terminology in more than one language in non-English speaking countries. Put another way, the information model provides a useful bridge between the technical and business sides of the organisation which can often use different languages. While there are many tools that can be used to create information models, few have support for multiple languages in the same model unfortunately.
Conclusion
The difference between information models (IMs) and data models (DMs) can be summarised as follows:
IMs provide a formal description of the organisation’s view of reality.
There should only be one IM per organisation, but there can be many DMs, usually one per system.
IMs define the terminology that should be used in documentation and software development.
DMs are optimised for the application that needs them. IMs help future-proof the solution but should not constrain the DM.
IMs can support multilingual organisations where the business units are using another language than English.
In future articles I hope to discuss how information models can be used in integration platforms to aid the definition of canonical data formats when performing data mapping and also enforcing data access controls. Another area where information models are very important is Master Data Management and in the use of Data Standards.
Having moved away from software development and design and more towards management of IT processes and services, I have found that Business Process Modelling is more applicable than UML to describing the kinds of processes I am encountering. This is not surprising, as UML is more IT-centric and I needed more flexibility to capture the realities of how things work in real life. Yes, you can use a combination of UML diagrams to capture a real-world process, but this is not as intuitive to non-IT people of which I encounter more often.
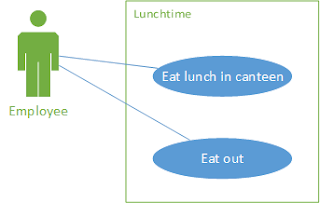
My first attempts at modelling a business process was using activity diagrams, sequence diagrams and use case models. The use case model defines all of the actors involved – both people and systems, the sequence diagram showed the message flow between them.
Figure 1 – Use Case Model Diagram
Figure 2 – UML Activity Diagram
However, this was still too low-level and I needed something that would capture the “big picture”. After all, a high-level process (e.g. a sales process) can naturally be broken down into sub-processes. Each level of detail provides meaning to the different layers of the organization as appropriate. Of course, UML is still important for helping to formally describe the resulting IT systems implementation.
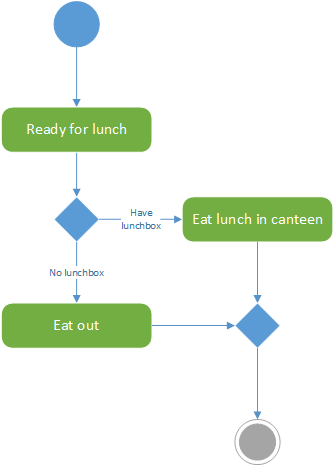
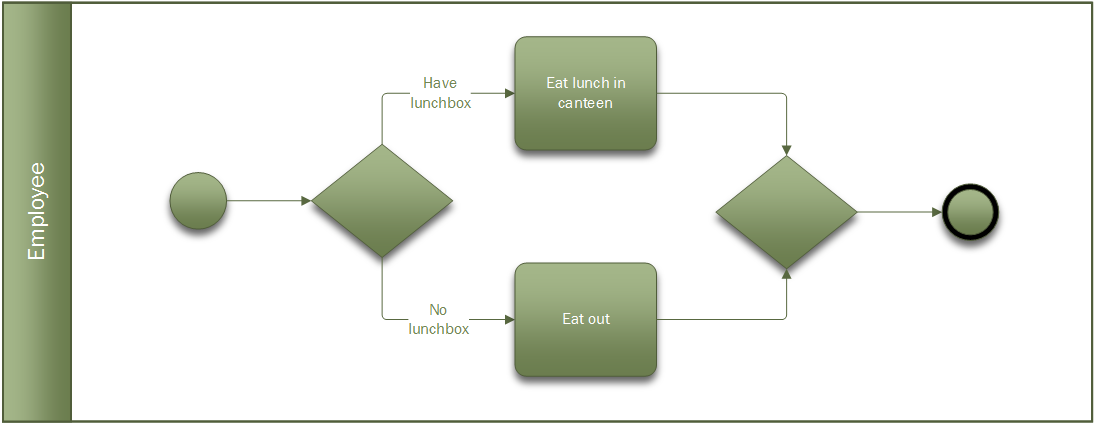
The nice thing about BPMN is that you can practice it all the time. With UML you generally want to be working on something IT related, but BPM can be applied to any process. For instance, how do people get something to eat for lunch? Do they eat out or have they brought a lunch box? This process can be described using BPMN.
Figure 3 – Process for eating lunch using BPMN
If BPM interests you and you are reading this article, the chances are that you are a pioneer in in your organization. BPMN is an industry-standard notation so if you are learning BPMN then the quicker you learn the rules and follow best-practice the more rewarding will be the result. I highly recommend the following two books:
Spending time formally documenting a process may seem like a waste of time in some ways. In the real world, situations change and people adapt or take shortcuts and the process model may be out-of-date in no time, but your BPMN model should not try to capture every detail or variation. More importantly, modelling a process using BPMN is an excellent aid to understanding how a given process currently works (even if it is dysfunctional). This process analysis can be much more complete when using a comprehensive notation like BPMN – if it can’t be modelled in BPMN then there is probably some wrong assumption or something hidden in the process that needs to be investigated. BPMN gives you the confidence to pursue a process analysis to its proper conclusion.
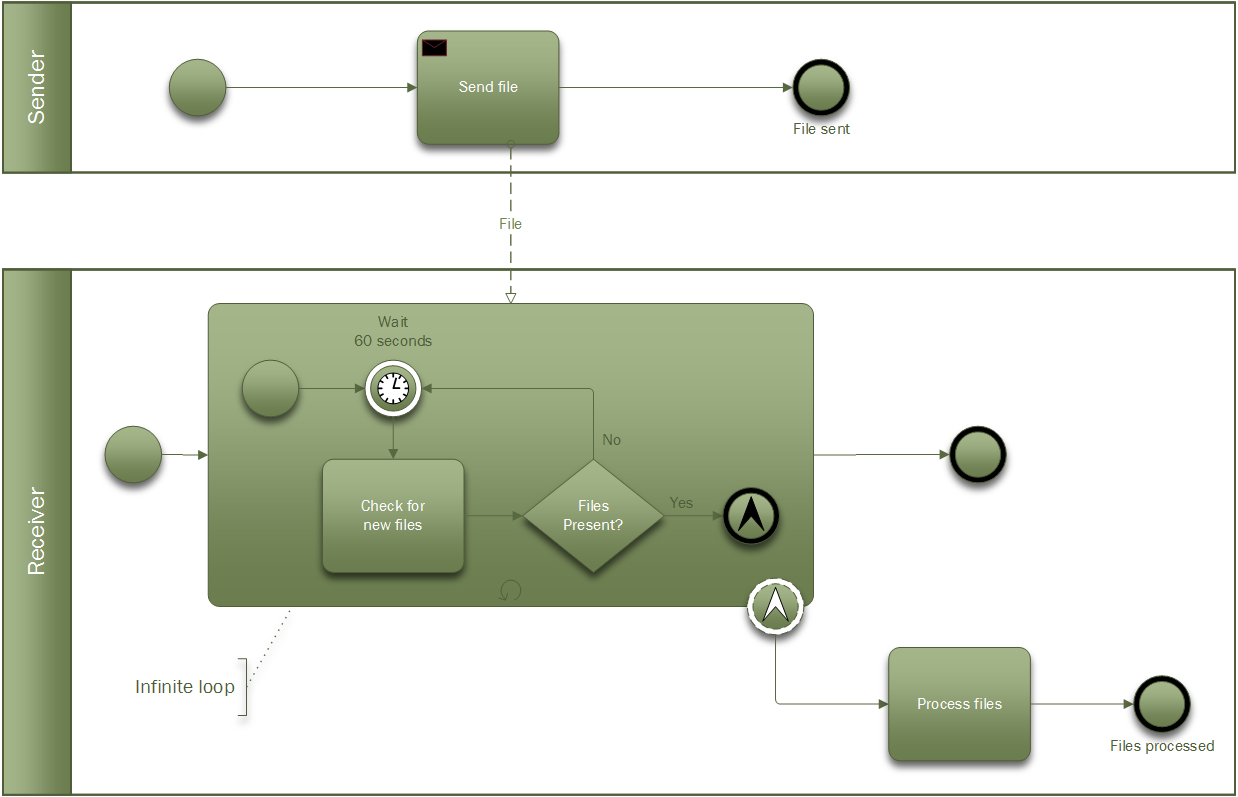
I will finish with an example of a process model I was grappling with recently. Systems integration is often done using messaging, typical of a Service Oriented Architecture. Files are transferred from one server to another and then imported into the recipient software system. (As this is an IT-centric problem I could of course have used UML to model this.) File transfer is either push or pull, in this case push. The sender places files on the recipient’s file system. The receiver checks for new files every few seconds and if it finds any it processes them.
Modelling system interaction in BPM it is called a collaboration. The collaboration is named after the process, in the case “File transfer”, and the lanes are named after the actors. The first thing I had to figure out was whether to use events to show that a message had arrived. At the same time the recipient is busy polling the directory looking for files, and will continue to do so as long as the service is available.
The sender and receiver are modelled as two separate processes. The sender sends the file using a message activity with a message flow symbol attached.
Figure 4 – File transfer using BPMN
The message is sent to the recipient’s polling subprocess which can generate a non-interrupting escalation event (ooh!) (the little arrow in the dotted circle) to trigger the next activity that processes the files. The subprocess is looped (the little circular arrow), so it will continue to run after the escalation occurs (forever in this case).
So how did I know how to use a non-interrupting escalation? Well, the non-interrupting part is just saying that the event does not interrupt the subprocess flow, i.e. polling will still continue when files have been found. The escalation part, just means that the polling process has found files and needs someone else to deal with them, so it notifies the parent process (escalation).
The diagrams were produced using Visio Professional 2016 which includes a function to validate the diagram according to BPMN 2.0 (“Check diagram”).
In my last article we looked at what factors influence a company’s choice of IaaS solution. A more advanced strategy would be to migrate to a SaaS with the potential for even bigger savings.
If a company is looking to upgrade an existing IT system then there should always be some research done into what cloud alternatives are available. More are more companies are offering cloud versions of their services, or someone else is offering an equivalent competing SaaS.
Compared to IaaS, SaaS takes management of the IT systems completely out of the hands of the IT department. So much so, that any executive with purchasing power can start paying-as-they-go for a cloud service. It requires no IT expertise to register for a Salesforce subscription for instance.
However, this is a flawed approach for two reasons, the first is that it undermines whatever IT strategy the company may have and can lead to a proliferation of SaaS subscriptions that provide overlapping functionality and are difficult to integrate. What we are talking about is IT governance. While SaaS simplifies the business case for using a new IT system (i.e. zero CAPEX aka “pay-as-you-go”) it still needs to be done in coordination with the IT function (e.g. the CIO). The second aspect of IT governance is security. While any decent SaaS provides good security functionality, it still requires the application of a security posture that is in line with the organisation’s security policies and standards.
To rephrase, if a company uses only SaaS solutions for its IT needs, then IT governance is reduced to managing the SaaS portfolio (which functionality is available where and how they could or should be integrated) and maintaining the organisation’s IT security posture.
Subscribing to a new SaaS is easy as it should be. The pay-as-you-go model simplifies testing a service, and the setup and roll-out of the service in the organisation is not under the same time-pressure as one that has required a huge upfront CAPEX. However, it is a different proposition if the company needs to migrate from an existing legacy system.
There are two types of migration, one from an on-premise product to the cloud version of the same product. This can happen because it is cheaper and/or the vendor has phased out the server version for the cloud version on the product. The other type of migration is to a cloud service based on a different product.
Regardless of which type of migration is being performed, there are some challenges (I hesitate to say limitations, read on) with leaving a legacy server-based solution. When a company owns and manages its own copy of a product, it has complete control over how it is deployed and integrated into the corporate IT environment. The product may provide APIs (or not) and there is the possibility to customise the product to meet the organisation’s needs. But the same product delivered as a SaaS will not allow the same customisation. And here is where SaaS really comes into its own I believe.
SaaS is very attractive from a licensing and management point-of-view, provided the company does not want to do a lot of customisations. Vendors, however, understand that one-size-fits-all will limit the number of customers they will have, so vendors invest heavily in providing lots of configuration possibilities. In the extreme, they can provide layers of abstraction and deliver what is essentially a toolbox of functionality that the customer can use to build their equivalent proprietary functionality. Jira Cloud is an example of a service that provides enormous flexibility when building issue-tracking workflows for instance.
Vendors will provide this toolbox-like functionality as long as there is a market willing to pay for it. However, this may still not be enough for customers with very specific needs. But cloud vendors are not done yet. They can also provide APIs such as REST to allow the customer to fulfil its requirements by encapsulating the custom functionality in a separate service. Jira Cloud and Salesforce Force.com provide this type of integration for instance.
And so here it is, the customer can migrate to the cloud using a standardised, configurable SaaS with an integration to a company-specific service that meets all of their requirements. Now, suddenly you have cost visibility! On one side you have a standard SaaS that probably provides 95% of the functionality for a very reasonable monthly cost, and on the other side the customisations that deliver 5% of the functionality but probably cost more per month.
But the whole point is not for the customer to have to migrate to the cloud in this way. SaaS makes the real cost of maintaining proprietary solutions painfully visible to management, with the result that there is more incentive to analyse why they are needed in the first place. And guess what, the organisation can often adapt their business processes to behave in a more standard fashion; after all cloud services exist because they are a successful way for lots of companies to leverage IT in their businesses.
In summary, when an organisation has to choose between making a work process change and making proprietary changes to on-premise IT-system, then its IT that most often gets the job. This creates a legacy that is dragged into the light when the company wants to leverage the benefits of very economical pay-as-you-go services. These customisations will acquire a very real maintenance cost and companies will only retain those that are essential. The IT department’s budget will start to correlate more with maintaining these customisations.
What does tomorrow’s IT department look like? I will explore this topic in another article.