A central tool in managing the team’s work is the Kanban board. The team owns their Kanban board and everything on it. It is there to visualise the team’s work, to provide a sense of control and create a sense of flow. So for example, if there is a bottleneck in testing, it’s there for the whole team to see and the team can collectively prioritise eliminating it.
In short, the Kanban board is a powerful tool for creating a sense of collective ownership in the team. But there are some ground rules that apply otherwise this effect is lost:
The tickets on the board represent the team’s work and what can be delivered by the team. The board must not contain work done by external parties (i.e. anyone not in the team).
The team must ruthlessly prioritise, rework or eliminate stuck tickets. Even one exception can lead to more exceptions, and before long flow is lost.
Bottlenecks mean “all hands on deck” to solve the problem and regain flow. Plus, it makes no sense to keep pushing more work into an already long queue. WIP limits can be applied to highlight bottlenecks, but usually common sense prevails.
Following these ground rules means that any member of the team, at a glance, can see the status of the team’s flow, and know that if there is a problem with the flow then it is a) within the power of the team to solve that problem, and b) that is more important than pulling the next ticket from Todo.
If the team do not follow these three ground rules, then it will be hard to create a sense of ownership when there are a whole bunch of exceptions to the rules that erode the team’s sense of control. It becomes someone else’s problem.
Put another way, if the team use Kanban properly then it will create a sense of flow that everyone in the team can identify with and which transcends the individual roles and specialist competencies that a cross-functional team naturally has. But fail to do this, and Kanban is just another messy backlog with unclear priorities that the team eventually stops paying attention to. Then it just becomes easier to pull the next ticket from Todo instead.
Deciding what technical improvements to make is always a challenge and one area that often requires attention is application performance. The de facto standard for delivering services is to used REST-based APIs and if you are using Amazon Web Services (AWS) then this will usually involves deploying an Elastic Load Balancer (ELB) in front of your backend application servers.
It is a good idea to take methodical (scientific) approach to fixing performance issues. So we want to look at the data and make good data-driven decisions about what problems to focus on. This article will describe how to get started with performance monitoring using AWS Athena.
TL;DR;
AWS Athena provides an SQL query interface to your ELB logs which allows advanced troubleshooting and pattern analysis:
Enable logging on the ELB.
Set a lifetime policy on the S3 bucket used for logging.
Let the logging run for a few days at least so you have some data to work with.
Set up the Athena database and table.
Craft your query in the Athena Query Editor.
Set up a scheduled job to get regular performance reports.
Costs
There are two costs associated with this solution:
Athena costs per TB of scanned data, which can be controlled using the storage lifecycle rule already mentioned and by crafting good SQL queries. https://aws.amazon.com/athena/pricing/
Step 1: Enable logging
By default logging is not enabled on the ELB. When it is enabled, the logs will be saved to an S3 bucket. Follow the instructions here:
It might take some time to understand how much log history you need or can afford. But it is good to know how to set up and modify it. Follow the instructions here:
Create the table with partition projection, this avoids having to manually add the partitions as you go.
Change the CREATE TABLE query to name the table “alb_log”. This will save some headaches later on when copying and pasting queries from others. Note that you can recreate the table at any time without losing data or saved queries.
Both the LOCATION and storage.location.template parameters should be changed to match the location of your ELB logs in S3.
To avoid typos in the location name, navigate to the S3 bucket and drill down into the parent of the year level directories. Then click on Copy S3 URI button and paste this into both locations in the CREATE query.
Set the projection.year.range to the current year and next year, e.g. “2022,2023”.
When the table has been created, click on the vertical ellipsis (“…”) beside the table name and select Preview table. If everything is working, then the results will show the latest 10 queries made to the application server.
Step 4: Find performance issues
Here is an example of a query that will find the top 100 slowest queries in the last week:
SELECT client_ip, request_url, target_processing_time FROM alb_log
WHERE (parse_datetime(time,'yyyy-MM-dd''T''HH:mm:ss.SSSSSS''Z')
BETWEEN DATE_ADD('day', -7, now()) AND now())
AND (target_processing_time >= 5.0)
ORDER BY target_processing_time DESC
LIMIT 100;
The frequency of requests that took longer than 30 seconds in the last week:
SELECT count(*) AS cnt, request_url, ROUND(AVG(target_processing_time),0) AS avg_time FROM alb_log
WHERE (parse_datetime(time,'yyyy-MM-dd''T''HH:mm:ss.SSSSSS''Z')
BETWEEN DATE_ADD('day', -7, now()) AND now())
AND (target_processing_time >= 30.0)
GROUP BY request_url
ORDER BY cnt DESC
LIMIT 100;
This is just the start. Querying in SQL means that there is a big community than can help you craft good queries that will meet your needs.
Step 5: Stay informed
Ideally you want to be getting regular performance reports from your application server, and to do that you can set up a scheduled task to run any arbitrary query on the ELB logs and have it sent to the team. We could use an AWS Lambda function, but in this example I will set up a pipeline in Buddy to run once a week and publish the results via email.
First, give Buddy permission to access Athena. Buddy has its own AWS account and you should follow the instructions for adding Buddy’s account as a trusted entity to AWS. The Buddy account will have a specific role that can then have policies attached to it which decides what the role can do. In this case I will use the standard policies to allow Buddy to run Athena queries and retrieve the query results from S3:
AWSQuicksightAthenaAccess policy
AmazonS3ReadOnlyAccess policy
Note that the AWSQuicksightAthenaAccess policy expects the S3 bucket name to start with “aws-athena-query-results-“. If that is not the case the create a bucket with that name and update the workgroup to use it instead. The old bucket can then be deleted.
In Buddy, create a AWS CLI action that runs a query and then copies the CSV result file from the S3 bucket to the Buddy pipeline.
sql_query="SELECT client_ip, request_url,
target_processing_time FROM alb_log
WHERE (parse_datetime(time,'yyyy-MM-dd''T''HH:mm:ss.SSSSSS''Z')
BETWEEN DATE_ADD('day', -7, now()) AND now())
AND (target_processing_time >= 5.0)
ORDER BY target_processing_time DESC
LIMIT 100;"
aws athena start-query-execution \
--query-string "$sql_query" \
--work-group "primary" \
--query-execution-context "Database=alb_db" \
> aws_out.json
execution_id=`jq -r .QueryExecutionId aws_out.json`
while true; do
aws athena get-query-execution --query-execution-id $execution_id > aws_out.json
execution_state=`jq -r .QueryExecution.Status.State aws_out.json`
case "$execution_state" in
"SUCCEEDED") break;;
"FAILED") exit 1;;
"RUNNING") sleep 10;;
esac
done
csv_file=`jq -r .QueryExecution.ResultConfiguration.OutputLocation aws_out.json`
aws s3 cp $csv_file athena_query_report.csv
The results can also be retrieved directly as JSON if desired:
In an earlier post I showed how a team can get started with Kanban by visualising and organising their work using post-its, and concluded with a look at managing WIP (work-in-process). In this article I want to broaden the discussion to look at some of the other features of Kanban that can help the team manage their work.
WIP is a problem for most teams, especially when release cycles are long (1 month or longer), but there are other factors that can affect flow and that can also contribute to a lot of WIP.
Categorising work
The Kanban board represents what the team are expected to deliver; therefore the work must be well-defined with clear acceptance criteria (as distinct from the discovery phase where ideas are still being explored and the scope is unclear). There is usually a week’s worth (or a sprint’s worth) of tickets ready to be pulled from the “To do” column.
Something I encounter frequently in teams is where developers pre-assign tickets to themselves that they know they will work on, but haven’t started yet. When I asked why they do this I learned that they want to know what was in their pipeline, what was coming up next. So, assigning the issue to themselves was their way of labelling the issue as being part of their domain, e.g. web development, or back-end development.
We talked about other ways of tagging the issue; Jira provides the Components field and Labels field to help categorise issues, and on the Kanban board it is possible to create “Quick filters” that will filter on these fields. For instance, the front-end developers were able to create a filter to that only showed “web” components. This turned out to be a great idea, something the whole team could use to find certain types of work on the board.
Using filters in this way also has the advantage of highlighting all of the work related to a specific component or label. And whereas a ticket can only be assigned to one person, there can be many components and labels set on a ticket, allowing it to be filtered in different ways.
Identifying bottlenecks
Even if the team manage to get WIP under control, it will still happen that bottlenecks will occur. After all, every piece of software development is unique and will have its own unique challenges with delivering it.
As a coach, I can talk to the team about what appear to be bottlenecks in the flow – with Kanban the problem is there for all to see. If the bottleneck is in testing, the developers may not see it as their problem to solve, until I point out that continuing to build more stuff that needs to be tested just adds to the bottleneck, and they will be waiting that much longer for the code to reach production. This usually gets the team thinking.
There are two things the developers can do in this case, either help out with testing or, do some technical improvement that does not require QA resources. In the best case, the developers use their skills to help automate some of the testing, a win-win for the whole team.
Flagging blockers
As I stated at the beginning, when a ticket is added to the board it should have a clear Definition of Done and clear acceptance criteria. But it will still happen that there is hidden complexity in the ticket and work on that ticket stops until the scope is clarified. What I see happen quite often is that the team moves stuck tickets to a separate “On hold/Blocked” column. This breaks the flow of work, now the team have to remember where the ticket was blocked, was it during development? Testing?
A better approach is to flag the ticket in the column where it is stuck. For instance, Jira provides a convenient “Add flag” option to highlight tickets that are stuck without changing its status. When the blockage is removed, the flag can be removed and work continues from where it left off. The ticket is also visually striking when is flagged, it demands attention, which it should.
Hidden complexity is just one reason why a ticket cannot move forward. There are other reasons, but they are all a result of the same thing: external dependencies. For instance, hidden complexity means going back to discovery with stakeholders, and stakeholders are not part of the team, they are an external dependency. This is not a bad thing, but it is important that the team understand their domain of control, and what can slow them down.
Understanding your domain of control
The essence of the Kanban board is that when a ticket is added to, the team can say “Yes, we can deliver that”. The work is clearly defined, but more importantly all the resources needed to deliver that piece of work are in the team: designers, developers, testers, devops, etc.
If that is not the case, then the team are relying on third parties (external to the team and/or external to the company) to get the feature into production. And every time the team need help from a third-party to move the ticket forward, they are essentially blocked because they have no control over the priorities a third-party has. So while some people work closely with the team, they are still not part of the team and so they block the team because they answer to another master with other priorities.
If a lot of tickets are being blocked, the tendency is to start working on something else, rather than solving the blockers, which just adds to WIP. Instead the team must relentlessly focus on removing the blockers, whether it means adding the necessary resources to the team, doing more in-depth discovery, or doing a more radical re-evaluation of the team purpose.
Managing risk
Finally, the Kanban board can be used to manage risk. In a nutshell, a lot of WIP means longer lead times, which increases the risk that priorities change before the feature is shipped, with the result that features are abandoned halfway through development which is an expensive way to run a business.
Regardless of what development process and release cycle the team uses, if there are a lot of tickets on the board it means that when something new is added, it will have to wait until all the work already on the board goes into production before it can be shipped.
Since the work on the board is supposed to be well-defined, it should be possible to make some ballpark estimate how long it will take to deliver everything on the board. Let’s say, your estimate is 3 months. Ask yourself, how confident are you that you will be able to deliver everything on the board before priorities change?
Some friends and I were talking about how well-organised a company might be, things like a clear hierarchy, well-defined processes, job satisfaction and so on. One thing that struck me was that some companies succeed despite their poor organisation, for instance (de facto) monopolies, but also disruptive companies that use IT to rapidly transform an industry. These companies are able to make so much money that they can operate very inefficiently and still make a profit. Competition is what drives companies to be more efficient as customers can shop around for the best prices and so companies can be forced to streamline their organisations to stay profitable.
Lean production is one way to streamline an organisation and is a core concept in the Agile way of working. Lean is so critical to Agile because it provides the flexibility needed by software development companies to adapt products continuously, especially in today’s web- and app-based product landscape. The threshold for a product reaching the market is now lower than ever, but competition is also never far behind, so the company that can adapt the fastest and keep their customers happy will win.
The essence of Agile is captured in the Agile manifesto and its underlying principles, and there are many tools and techniques that can be applied to support an Agile way of working. Often though an Agile coach will focus entirely on the tools and techniques as this is a tangible, measurable way to see Agile in action. And if the team can see the benefits of working in an Agile way then they will continue to do so long after the Agile coach has gone. But, this is rarely the case. Why? To understand the problem, I return to the first statement in the manifesto:
Individuals and interactions over processes and tools
What I interpret this to mean is that it is paramount to build relationships with your stakeholders, your boss, your team and anyone else that can impact the success of your mission. This is good advice in any company, but it is absolutely essential for sustaining an Agile way of working in the long term. Let me explain why this is so.
Every software product is a one-off, unique, therefore the success of a product cannot be guaranteed in advance since it has never been built before. This is why iterative development and the resulting customer feedback are so important, so we can adapt the product to as we go, using customer happiness as a measure of success. What is often missed is that customer feedback may also be telling us that we need to adapt our organisation too.
Adapting the organisation is really about changing the processes used to create and deliver value. This kind of change will affect multiple teams or even departments and requires coordination across domains of responsibility. It is also not uncommon for these domains to be jealously guarded territorial domains. In traditional organisations that exercise a command and control management style, change can be effected by issuing the necessary directives, restructuring and retasking teams and departments to improve efficiency. However, command and control structures respond too slowly to the rate of change needed in a rapidly evolving software ecosystem.
A powerful alternative to this is to create empowered teams, delegating responsibility to the people that can respond the quickest to the customers’ feedback. However, if a team identifies improvements that impact the way other teams work, they do not have the mandate to force those teams to make any changes. This is where the need for good relationships with your stakeholders comes into play. What I mean here is the existence of personal relationships between the team leads, and that can and usually does take time to cultivate. Ideally, you want to start developing these types of relationships from Day 1, because being Agile is about being able to continuously adapt to your customers’ needs, and you will need to work closely with other teams to make that happen on a continuous basis.
This then is the reason then why Agile tools and processes are gradually abandoned, not because the are not useful, but because teams become disillusioned when all of the efforts to improve their team’s velocity, lead time and quality are erased by another team’s inefficiency. Improving the efficiency of another team can only be done when a good relationship exists between the teams — there must be a sense of trust between the teams because changing how they work requires that they trust that the changes are for the good of the company and not only for the good of another team. Failing that, it is good to have a fallback plan: escalation. And if you hope that your manager can help solve the problem instead then you should also work to have a good relationship with them too.
In summary, software organisations must continuously adapt to their customer’s needs in order to win, and I have shown that managers must foster a culture that focuses on individuals and interactions to do so. Agile tools and processes will help individual teams improve their efficiency, but personal relationships will allow organisations with empowered teams to effect even greater improvements across domains of responsibility. Or to put it more concisely:
Individuals and interactions over Agile processes and tools
Bringing together the necessary disciplines to form high-performance cross-functional teams is a key management decision when creating good software products. All software products are one-offs, unique, so having the product owner, designer, developers and testers in the same team is the most effective way to make essential trade-offs when delivering “good enough” solutions. Add to this the importance of early feedback that only comes from doing iterative releases, and an empowered cross-functional teams becomes the best vehicle for success in a highly-competitive marketplace.
True product teams do exist, but more often they are really just delivery teams, or at best feature teams. The distinction can be captured with the question: Are we giving the teams problems to solve or solutions to build? True product teams are trusted to come up with the best solutions to meet business objectives. However, lack of trust is often a big issue, but so is a lack of maturity. Product teams take time to form and usually need coaching. Management should also focus on the teams’ outcomes and allow them to do their jobs without too much interference.
One way of organising the company is to give the product discovery activities to a separate “Product Team” with the necessary competencies: POs, designers, business analysts, etc. This team should then come up with the winning product concepts for the cross-functional teams to build. This reduces the other teams to being delivery teams doing exactly what the “Product Team” decides. One side-effect of this is that there is now no room for doing experiments in the teams since the course is already plotted.
The problem with this model is that “Product Team” will have been given a purpose with the expectation to deliver something useful. There is then pressure on the team to come up with guaranteed money-spinners for the company, and they will work hard to describe a viable product solution, often using high-fidelity prototypes. This results in a large chunk of work, essentially a requirements document, even if it is in graphical format, that must be handed over to the feature/delivery teams, who must then start over, making the necessary trade-offs and reorganising the work into iterations. The delivery teams may well use Agile techniques and tools to build the solution, but it is really just operating in a big waterfall process.
The best products are built by teams that care about the products they build and the customers that use them. Naturally, they will have insights and ideas about improvements (experiments) that can be made to the product, and in a true product team this is how discovery and delivery are combined to deliver just enough software to satisfy the customers’ needs. However, in the waterfall process described above the ability of the delivery/feature team to influence the product is limited because a) the waterfall process is one-way and b) the “Product Team” see concept work as being their sole responsibility. This is a major cause of frustration for the teams and as a result there is a big risk that the most engaged team members will leave to find companies where they are allowed to make impact on the product.
The PO is a key member in a cross-functional team. If the team is a true product team then the PO will take total ownership of the product and be involved in all aspects of the product lifecycle, from concept and feature development to back-office processes and support tools, legal requirements, and more. However, in the waterfall process above, they essentially have only two roles, one is as a delivery manager in the delivery team, the other as a feature expert in the “Product Team”. Neither role covers the totality of a true Product Owner role; in fact the waterfall process is really just driving a feature factory. Of course, delivering customer value is the most important thing the team can do, but it is not the only thing, the problem is that the waterfall process does not support delivering other types of value.
In giving responsibility for these two closely interlinked processes of discovery and delivery to different teams, management is obliged to ensure that a good relationship exists between the teams to ensure success, and that the one-way waterfall process becomes instead a two-way exchange of ideas between partners. In the worst case, management are de facto prioritising feature delivery over every other type of work, ignoring the fact that different types of value exist, value which can have just as much impact on the company fortunes as feature development.
Companies already in the situation described above can try to improve it, but a sense of trust has to exist between all of the teams to do so, because changing how we work requires that we trust that the changes are for the good of the company and not only for the good of one team. This requires strong management support.
Jira now provides a powerful way to build automated process flows using Automation rules. These rules can be triggered in different ways; one such way is when an issue is transitioned. However, automation rules are not the only thing that can be triggered on an issue transition, Jira Workflows have Post functions that trigger when an issue transitions from one state to another. So what is the order of execution in that case?
The post functions always contain a “Fire a Generic Event event” function or similar which Automation rules can listen for, but regardless of where in the order of post functions the event is fired, the automation rules are always executed after the post functions have been executed. This I learned while discussing the Automation rule behaviour in the Jira support forums, specifically all the post-functions in a transition are executed as an atomic transaction.
On reflection this is not so strange, triggering and listening for events is an asynchronous process, meaning that the process triggering the event will not wait for the listener (or listeners) to act. And if the post functions were not executed as an atomic transaction, then there would be a risk that an automation rule could trigger at some arbitrary point during the execution of the post functions, creating a race condition with undesirable consequences.
In this post I want to talk about fidelity, meaning the resolution we give to our product prototypes. Marty Cagan talks a lot about the different types of prototypes that can and should be used during discovery. A prototype should only just be good enough (i.e. have high enough fidelity) to verify an idea. We don’t want to spend any more time making it than necessary, because in the end we will throw it away once we build the real product.
To understand if a feature will be valuable and usable, the designers can create wireframes/mock-ups/prototypes in a tool like Figma. It allows the designers to create realistic screens and also run simulations of the real app (just the flows, no data). The risk is that the designers go all-in, creating high-fidelity prototypes that the developers must treat essentially as a requirements document, with all the difficulties that that entails:
The developers have to build in increments (screen-by-screen), rather than being able to deliver iteratively (starting with a simple story and elaborating).
Changes to the design means that a large prototype has to be frequently updated, requiring the team to spend time figuring out how to maintain the prototype rather than spending time collaborating on delivery of the next story.
Also, the more waterfall the process is, the more overloaded the prototype becomes with all the information the developers need to build the product. The result is a very high-fidelity prototype that actually contains many different types of information:
The flow (process) the user follows
The structure of the information presented in each screen
The graphical details (colour scheme, copy, etc.)
The Agile way
So how should we design prototypes as part of an iterative development process? There is still the need to capture the conceptual integrity; the team still need prototypes to verify the value and usability of potential solutions. The answer lies in the fidelity of the prototypes.
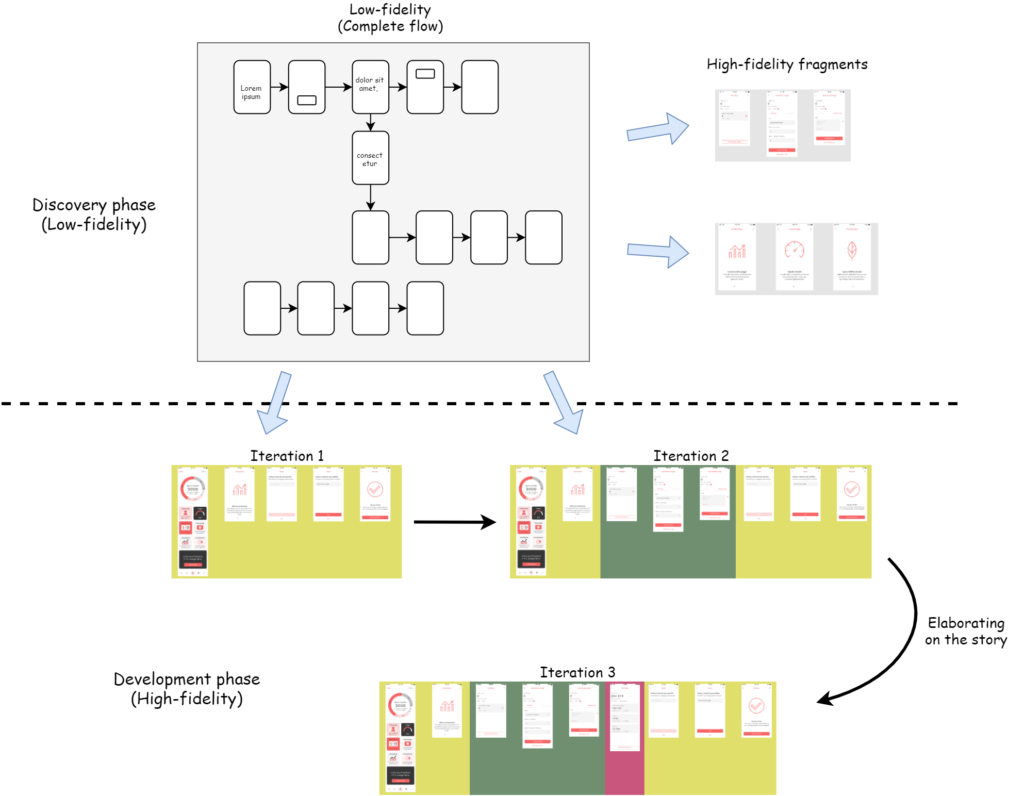
To verify the conceptual integrity of the solution, it is enough to capture the flow, name the activities and identify the states the customer or feature is in. High-fidelity prototypes would be replaced with simple boxes, arrows and labels, and would actually more resemble the process diagrams created using BPMN.
If more fidelity is needed at this stage, in order to verify usability for instance, then it should be added to those screens where it is needed, rather than the whole prototype. But even if creating a full-scale high-fidelity prototype is justified at this stage, it should still not be delivered as a big-bang to the development team for the reasons stated above.
The story starts here
Once the team have identified a valuable, usable, feasible feature that can be built, the next step is to break down the work into smaller pieces, eventually arriving at INVEST-type stories that can be used to create potentially shippable software at every iteration. These stories should be supported by corresponding prototypes which contain all the structure and graphical details needed by the developers to be able to build the feature. The key here is that the designer creates specific prototypes for each story that the team have defined, rather than just referring to some combination of screens in an existing full-scale high-fidelity prototype.
Now the team will have a story-size high-fidelity prototype that only contains enough information for the story they will work on next. Even if the details change, it will be on a much more manageable scale. In fact, creating this small high-fidelity prototype should not be the end of the collaboration between the designer and the developers. They should continue to work closely together during development and make changes directly to the product rather than updating the prototype (which will be obsolete as soon as the story is finished). This avoids the need for any elaborate maintenance procedures.
The flip-side of this is that the earlier full-scale low-fidelity prototype will also be easier to maintain because it only represents the flows, which also should be quite stable even as discovery continues during the development phase. In other words, it is the structure of information and graphical details that are most volatile and should therefore be modelled as close in time to development as possible (“just-in-time”).
Summary
Using this just-in-time approach, the designers would still do about the same amount of work as before with the difference that the more volatile design elements would be created in collaboration with the team and the most volatile elements would not be captured in Figma at all, but added directly to the product in collaboration with the developers, e.g. using pair-programming.
The purpose of a reference architecture is to identify the architectural principles that apply when creating a sustainable and scalable solution. As new additions are made to the solution, the reference architecture becomes the yardstick that all solution proposals can be measured against and so enable a fair comparison of ideas.
A key test of the principles used to create an architectural model is whether they display conceptual integrity. Proposed solutions and additions to the solution must respect the conceptual integrity and show where they deviate from said principles as well as motivating why it was necessary to do so.
Deviating from these architectural principles is often (well-)motivated for reasons of time and cost when implementing the solution. However, without an explicit reference architecture one cannot measure the effect of these compromises, compromises that generally result in higher maintenance costs. And the larger the deviations from the reference architecture, the greater the risk for higher maintenance costs and the harder it will be to continue developing and scaling up the solution in future.
For over time, the tendency is always towards greater and greater divergence between the solution and the model; until finally the conceptual integrity of the solution can no longer be discerned. How then do we preserve the conceptual integrity? By training and information dissemination, what is known as shared understanding as preached in the Agile world. The development team must share the same picture of the reference architecture if it is going to be maintained going forward; and it will also be much easier to explain how a solution works if it adheres to architectural principles compared to one that does not.
An essential part of a reference architecture is the creation of architectural artefacts, such information models, state machines, process diagrams and so on. Using standard modelling notation such as UML and BPMN reduces the risk for ambiguity and makes knowledge sharing that much easier.
Where to start? Try to identify what type of solution it is you are building. Does it fit into a known pattern? Try to find the appropriate technical literature (in book format and online) that provides a frame of reference (including vocabulary), and use it to create a reference architecture which can then be applied to the solution.
I recently read an article about how to help someone get back to work after a long absence, perhaps due to illness or burnout. There was lots of good advice, such as keeping colleagues informed about adjustments to working hours and limiting responsibilities among others things. But what struck me was how a lot of the advice reminded me of the Agile way of working:
create clearly defined tasks
allow space to work on one thing at a time
provide support with prioritising
do not set short deadlines
set a clear plan for the week and a review at the end of the week
ensure delegation of tasks is done via a single channel
This could be from the Kanban playbook. To put it in Agile terms:
Tasks should have a clear definition of done
Developers should pull tasks, not have them pre-assigned
The Product Owner prioritises all work
Focus on outcomes not deadlines
Set clear goals and use daily stand-ups to ensure progress
Nobody outside the team can assign work to the developers
So you could say that creating flow does not just improve the team’s efficiency, it also contributes to the continued well-being of your employees.
I use the INVEST criteria to help teams define good User Stories. This would normally be sufficient to get any one story into production, but in the case of a new feature (or MVP) this has frustratingly not been enough; the stories just pile up in a feature branch until the team feel there is enough of them to deliver real value to the customer.
I have discussed with the teams how they can enlist the help of alpha and beta testers to get early feedback on new features that are not functionally complete. Here I add that the feature should still possess conceptual integrity. For instance, the first story in the feature might just allow the customer to to log in and log out. This does not deliver any real value to the customer, but it is testable, and it possesses conceptual integrity.
There are some obvious signs when this early testing doesn’t happen: the team hasn’t released anything for a month or two, the stories have been piling up in the Done column, and the PO is feeling a bit stressed. In these situations, the coach can ask the team:
What is stopping the team releasing something tomorrow to customers, friendly or otherwise?
This always starts an interesting discussion and the team usually identifies a (short) list of things to do to get the unfinished feature in front of some friendly customers. This gives the team a much-needed feeling of achievement, but more importantly they can start getting real feedback on the new feature.
This is a win for the coach, but it is still a reactive process. How can I make this a proactive part of the software delivery process? What I want is to encourage the team to really think about their Definition of Done much earlier. What I am hoping for is that the team will set a goal that goes something like this:
The stories the team prepare during backlog refinement must be delivered to customers (internal users, early adopters, etc.) as soon as each story is finished.
So from now on I will include “delivery” in my discussions with the teams by extending the definition of the criteria for a good User Story: Independent, Negotiable, Valuable, Estimable, Small, Testable and Deliverable; or INVESTeD for short.
This builds on a definition that is already familiar to the teams and so it will be natural to think about how to meet this criteria right from the start.